一般的网页展示的图片无非就是两种形式:<img> 标签 或者通过 CSS 属性 background-image 来设置,像这种类型的图片可以安装一个浏览器插件就能够全部下载。
但是有些页面渲染图片的方式比较特别,例如:canvas 绘制 、 WebGL 等,一般的浏览器插件是获取不到的。这也是我最近遇到的一个问题,所以分享一下我的解决方式:
网络请求面板中查看
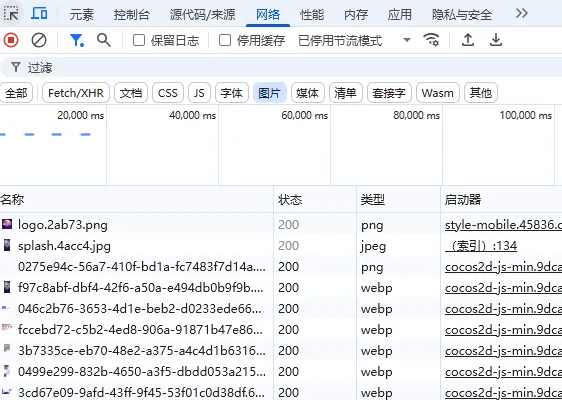
无论用什么方式渲染的图片,每张图片都会发起一个网络请求,所以这些图片都能在浏览器的网络请求面板中找到:
按
F12或者右键鼠标点击检查再或者按Ctrl + Shift + i打开开发者模式,找到网络请求面板选择图片,然后刷新一下页面,这样就能看到这个页面下展示的所有图片了
最简单的方式就是点击请求中的图片一张一张去下载,但是如果图片很多的情况下就会让人抓狂!!!
Node.js 脚本下载
首先介绍一个很重要的库:Puppeteer,用于通过 DevTools 协议控制 Chromium 或 Chrome 浏览器,实现自动化操作。它提供了控制浏览器的 API,也就是说我可以通过这个库批量下载网络请求面板中的所有图片。
amazing!
准备
1、初始化 npm
npm init -y2、安装 puppeteer
npm install puppeteer编写脚本
引入相关模块,除了 puppeteer 要单独下载,其它模块都是 Nodejs 内置模块
const puppeteer = require("puppeteer");
const fs = require("fs");
const https = require("https");
const http = require("http");
const path = require("path");创建一个目录用于保存图片
const saveDir = path.resolve(__dirname, "imgs");
if (!fs.existsSync(saveDir)) {
fs.mkdirSync(saveDir);
}启用浏览器实例,打开一个新的标签页访问目标页面,监听页面中的所有网络响应,将图片请求地址收集起来。
const browser = await puppeteer.launch();
const page = await browser.newPage();
const urls = new Set();
page.on("response", async response => {
const url = response.url();
const contentType = response.headers()["content-type"] || "";
if (contentType.startsWith("image")) {
urls.add(url);
}
});
// 这里填写页面地址
await page.goto("https://xxx.com/", { waitUntil: "networkidle0" });等待 5s 确保图片都收集完成
function wait(seconds) {
return new Promise(resolve => {
setTimeout(resolve, seconds * 1000);
});
}
await wait(5);实现一个下载图片的函数,并执行下载
function downloadImage(url) {
return new Promise((resolve, reject) => {
const protocol = url.startsWith("https") ? https : http;
// 去掉 query 参数
const filename = path.basename(url.split("?")[0]);
const filePath = path.join(saveDir, filename);
protocol
.get(url, res => {
if (res.statusCode === 200) {
const fileStream = fs.createWriteStream(filePath);
res.pipe(fileStream);
fileStream.on("finish", () => {
fileStream.close();
resolve(filename);
});
} else {
res.resume(); // 清理缓存
reject(new Error(`Download Error ${res.statusCode}`));
}
})
.on("error", err => {
reject(err);
});
});
}
const downloadPromises = [...urls].map(url =>
downloadImage(url)
.then(filename => {
console.log(`✅ Download Success: ${filename}`);
})
.catch(err => {
console.error(`❌: ${url}`, err.message);
})
);
await Promise.allSettled(downloadPromises);所有图片下载完成之后关闭浏览器
await browser.close();
console.log("🎉 All images saved to imgs");执行脚本
node download.js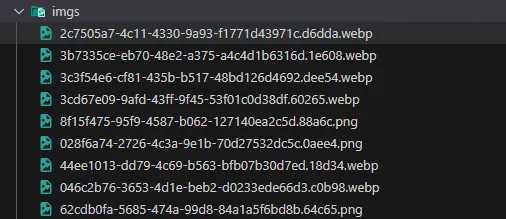
小结
通过以上这种方式,轻松获取到页面中所有的图片,只要页面加载了的图片就能够被捕捉并下载下来,如果你也遇到过无法保存图片的情况,不妨试一试!
Puppeteer 库的功能还有很多,例如保存页面截图等等,这里只是用到了它的一小部分功能,其它功能可以自行探索。